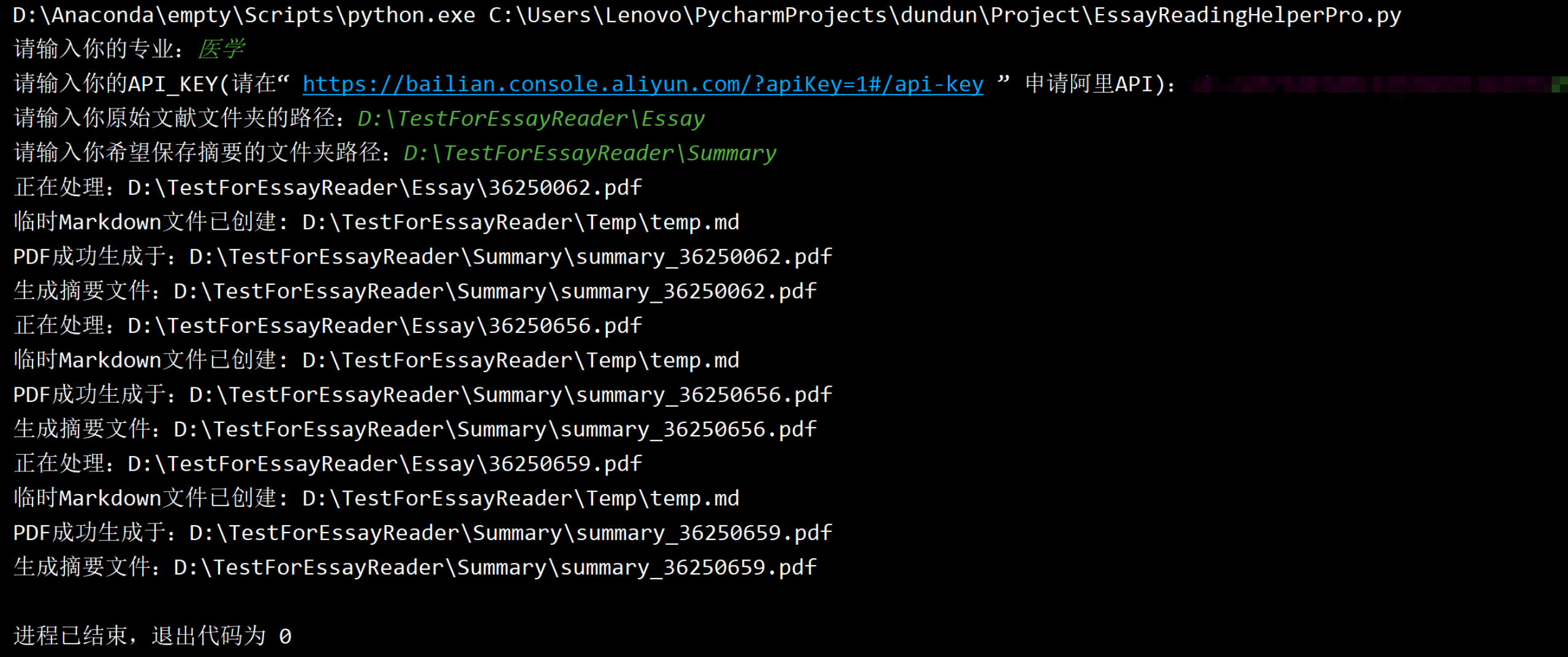
项目背景
在视频内容分析领域,我们常常需要从长视频中快速定位特定场景或画面。传统方法依赖于人工逐帧查看或基于元数据的简单搜索,效率低下且无法应对复杂语义查询。CLIP(Contrastive Language-Image Pretraining)模型的出现为这一领域带来了新的可能性,它能够理解图像与文本之间的语义关联。
笔者基于HuggingFace的CLIP模型开发了智能视频帧匹配系统,该系统可实现:
- 自动解析视频文件(支持MP4/AVI/MOV等常见格式)
- 实时计算文本描述与视频帧的语义相似度
- 智能定位最佳匹配帧并支持可视化预览
- 一键保存关键帧为JPG图片
开发思路
本地模型加载模块
考虑到实际部署时的网络稳定性问题,系统采用本地化模型加载方案:
- 使用
transformers库加载预训练的CLIP模型(clip-vit-base-patch32) - 设置本地模型缓存路径(E:\clip),包含完整的模型文件:
1
2LOCAL_MODEL_DIR = r"E:\clip"
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32").to(device) - 异常处理机制:模型加载失败时,提示缺失文件清单
多模态编码模块
文本编码
文本编码是将用户输入的英文描述转化为高维语义向量的过程。CLIP模型使用Transformer架构对文本进行编码,具体步骤如下:
- 文本预处理:将用户输入的英文描述(如 “a waitress standing in front of a restaurant”)进行分词和标准化处理。
- Tokenization:将文本转换为模型可理解的Token序列,每个Token对应一个唯一的ID。
- 特征提取:通过多层Transformer编码器,将Token序列映射为固定长度的语义向量(本项目中维数为512)。
1 | inputs = processor(text=texts, return_tensors="pt", padding=True).to(device) |
图像编码
图像编码是将视频帧转化为视觉特征向量的过程。CLIP模型使用Vision Transformer(ViT)架构对图像进行编码,具体步骤如下:
- 图像预处理:将视频帧从BGR格式转换为RGB格式,并调整大小为模型输入要求。
- 分块处理:将图像划分为多个小块(Patch),每个小块作为一个输入单元。
- 特征提取:通过多层Transformer编码器,将图像块序列映射为固定长度的视觉特征向量(本项目中维数为512)。
1 | inputs = processor(images=[pil_image], return_tensors="pt", padding=True).to(device) |
相似度计算
相似度是衡量文本描述与视频帧之间语义匹配程度的关键步骤。CLIP模型通过以下方式实现:
- 向量对齐:将文本特征向量和图像特征向量映射到同一语义空间。
- 余弦相似度:计算两个向量的余弦相似度,公式如下:

- 匹配分数:相似度值范围在[-1, 1]之间,值越接近1表示匹配度越高。
源码
1 | import torch |
使用说明
环境要求:
- 请安装Python 3.8+
- 安装依赖库:
torch,transformers,opencv-python,pillow - 如希望利用显卡进行加速计算,请安装CUDA和CUDNN
准备步骤:
- 下载CLIP模型文件至本地目录
- 准备一个您要处理的视频,并确保视频文件路径不包含中文
- 准备一个保存最佳匹配帧的路径
输出结果示例
笔者以本人所在学院的宣传片为例,其中有一段是游泳的片段,笔者尝试利用该程序找到游泳的片段。
首先按照要求输入CLIP模型的地址、视频地址和导出图片的地址,然后系统开始运行。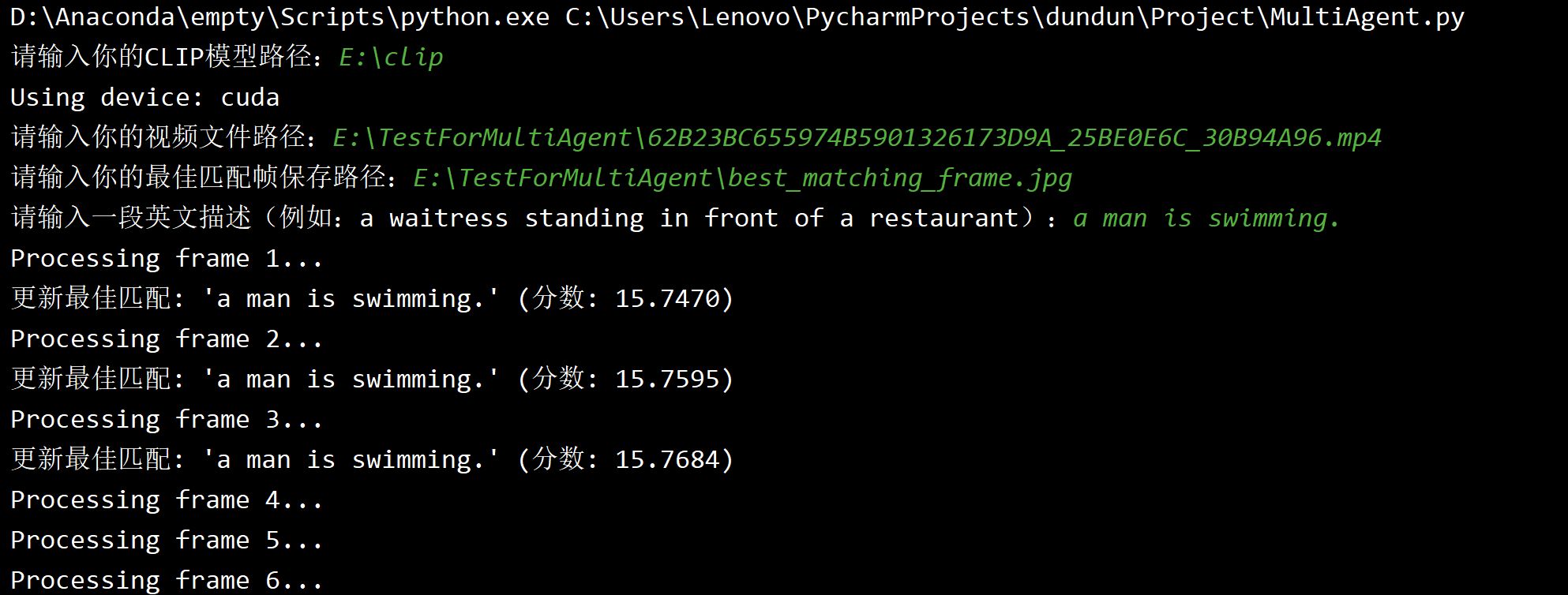
等到处理至游泳片段后,匹配分数不断刷新。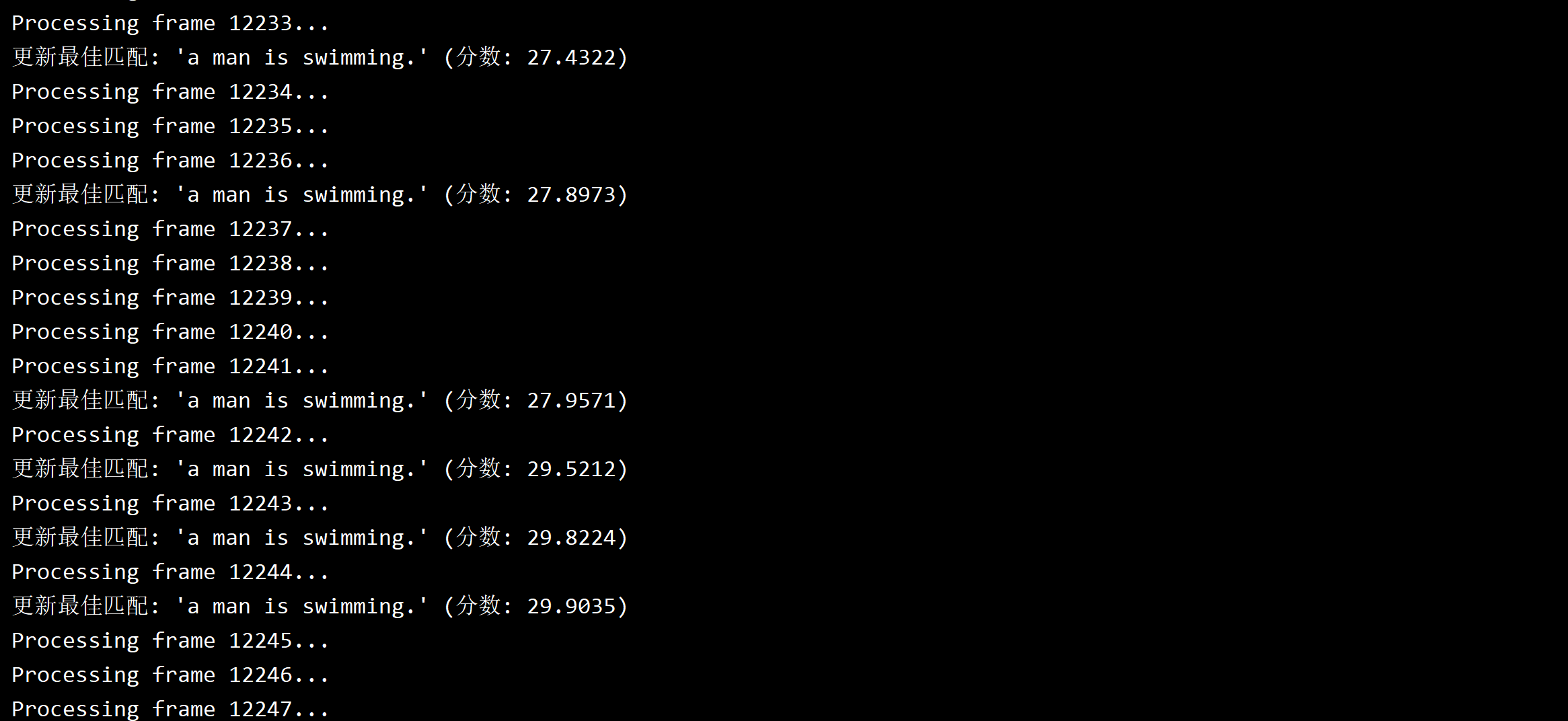
程序运行完毕,最匹配的那一帧会自动弹出。

键盘输入y之后,图片自动保存在设置的路径中。
技术优势
- 多模态对齐:CLIP模型通过对比学习实现了文本和图像在语义空间的对齐。
- 高效计算:利用GPU加速,实时处理视频帧并计算匹配分数。
- 语义理解:能够捕捉复杂的语义关系,而不仅仅是简单的关键词匹配。
备注
本项目是笔者在学习了一点大模型技术后,利用不到半天时间开发的小型应用。这只是使用多模态大模型的一个小练习,且市场上已经有一些不错的产品实现了本项目的功能(如百度网盘自带的“云一朵”助理)。
这篇文档会先在笔者的个人博客上发布,稍后会整理并发布在我的Github上,欢迎读者在Github社区提交issue讨论改进方案。