1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
| import os
import subprocess
import PyPDF2
import re
import tiktoken
from openai import OpenAI
def extract_useful_text_from_pdf(pdf_path):
all_text = []
try:
with open(pdf_path, "rb") as f:
reader = PyPDF2.PdfReader(f)
for page in reader.pages:
text = page.extract_text()
if text:
lines = text.splitlines()
if len(lines) > 2:
lines = lines[1:-1]
page_text = "\n".join(lines)
all_text.append(page_text)
except Exception as e:
print(f"读取PDF出错:{e}")
return "\n".join(all_text)
def split_into_chunks(text, max_tokens=8000):
tokenizer = tiktoken.get_encoding("cl100k_base")
paragraphs = re.split(r'\n\s*\n|\r\n\s*\r\n', text.strip())
chunks = []
current_chunk = []
current_token_count = 0
for para in paragraphs:
if not para.strip():
continue
para_tokens = len(tokenizer.encode(para))
if para_tokens > max_tokens * 0.8:
sub_paras = re.split(r'(?<=[。!?;]) +', para)
for sub_para in sub_paras:
sub_tokens = len(tokenizer.encode(sub_para))
if current_token_count + sub_tokens > max_tokens:
chunks.append("\n\n".join(current_chunk))
current_chunk = [sub_para]
current_token_count = sub_tokens
else:
current_chunk.append(sub_para)
current_token_count += sub_tokens
else:
if current_token_count + para_tokens > max_tokens:
chunks.append("\n\n".join(current_chunk))
current_chunk = [para]
current_token_count = para_tokens
else:
current_chunk.append(para)
current_token_count += para_tokens
if current_chunk:
chunks.append("\n\n".join(current_chunk))
return chunks
def summarize_document(text):
CHUNK_MAX_TOKENS = 8000
SUMMARY_MAX_TOKENS = 8192
chunks = split_into_chunks(text, max_tokens=CHUNK_MAX_TOKENS)
all_summaries = []
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
for i, chunk in enumerate(chunks):
try:
prompt = (
f"请阅读以下文献的第{i + 1}部分,用中文返回文献框架的markdown源代码,并且每个标题下要把文章中这部分内容做一个简单的概括。 请一定注意:\n"
"1.除了markdown源代码之外,任何内容都不要输出。\n"
"2.输出语言必须为中文。【非常重要!】\n"
"3.用多级的逻辑结构(一级标题、二级标题甚至三级标题)来总结原文的框架,尽可能丰满你的框架\n" + text
)
response = client.chat.completions.create(
model="qwen-turbo-2024-11-01",
messages=[
{"role": "system",
"content": f"你是一个{area}领域的文献分析助手,擅长从长文档中提取结构化框架并生成技术性摘要。"},
{"role": "user", "content": prompt}
],
temperature=0.4,
top_p=0.7,
max_tokens=SUMMARY_MAX_TOKENS,
frequency_penalty=0.5
)
summary = response.choices[0].message.content.strip()
all_summaries.append(summary)
except Exception as e:
print(f"第{i + 1}部分处理失败:{e}")
all_summaries.append(f"## 第{i + 1}部分摘要生成失败\n")
final_summary = "\n\n".join(all_summaries)
if len(final_summary) > SUMMARY_MAX_TOKENS * 2:
try:
response = client.chat.completions.create(
model="qwen-turbo-2024-11-01",
messages=[
{"role": "system", "content": "你是一个摘要精炼专家,擅长将多个章节摘要整合成连贯的完整文档摘要"},
{"role": "user", "content": f"请将以下分块摘要整合为完整的文献框架,你只能输出一段完整的markdown代码,其他的都不要输出:\n{final_summary}"}
],
temperature=0.3,
top_p=0.8,
max_tokens=SUMMARY_MAX_TOKENS
)
return response.choices[0].message.content.strip()
except:
return final_summary
return final_summary
def clean_markdown(md_text):
if md_text.startswith("```") and md_text.rstrip().endswith("```"):
lines = md_text.splitlines()
return "\n".join(lines[1:-1])
return md_text
def convert_markdown_to_pdf(markdown_text, output_path):
temp_md_path = r"D:\TestForEssayReader\Temp\temp.md"
markdown_text = clean_markdown(markdown_text)
try:
with open(temp_md_path, "w", encoding="utf-8") as f:
f.write(markdown_text)
print(f"临时Markdown文件已创建: {os.path.abspath(temp_md_path)}")
subprocess.run(
[
pandoc,
temp_md_path,
"-f", "markdown",
"-o", output_path,
"--pdf-engine=xelatex",
"-V", "CJKmainfont=Microsoft YaHei"
],
check=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
text=True,
shell=True,
encoding = 'utf-8',
)
print(f"PDF成功生成于:{os.path.abspath(output_path)}")
except subprocess.CalledProcessError as e:
print(f"转换失败,错误详情:\n{e.stderr}")
raise
except Exception as e:
print(f"操作出错:{str(e)}")
raise
finally:
if os.path.exists(temp_md_path):
os.remove(temp_md_path)
def find_pandoc():
try:
subprocess.run(["pandoc", "--version"], check=True, stdout=subprocess.PIPE)
return "pandoc"
except FileNotFoundError:
common_paths = [
r"C:\Program Files\Pandoc\pandoc.exe",
r"C:\Users\{}\AppData\Local\Pandoc\pandoc.exe".format(os.getenv("USERNAME"))
]
for path in common_paths:
if os.path.exists(path):
return path
return None
def main():
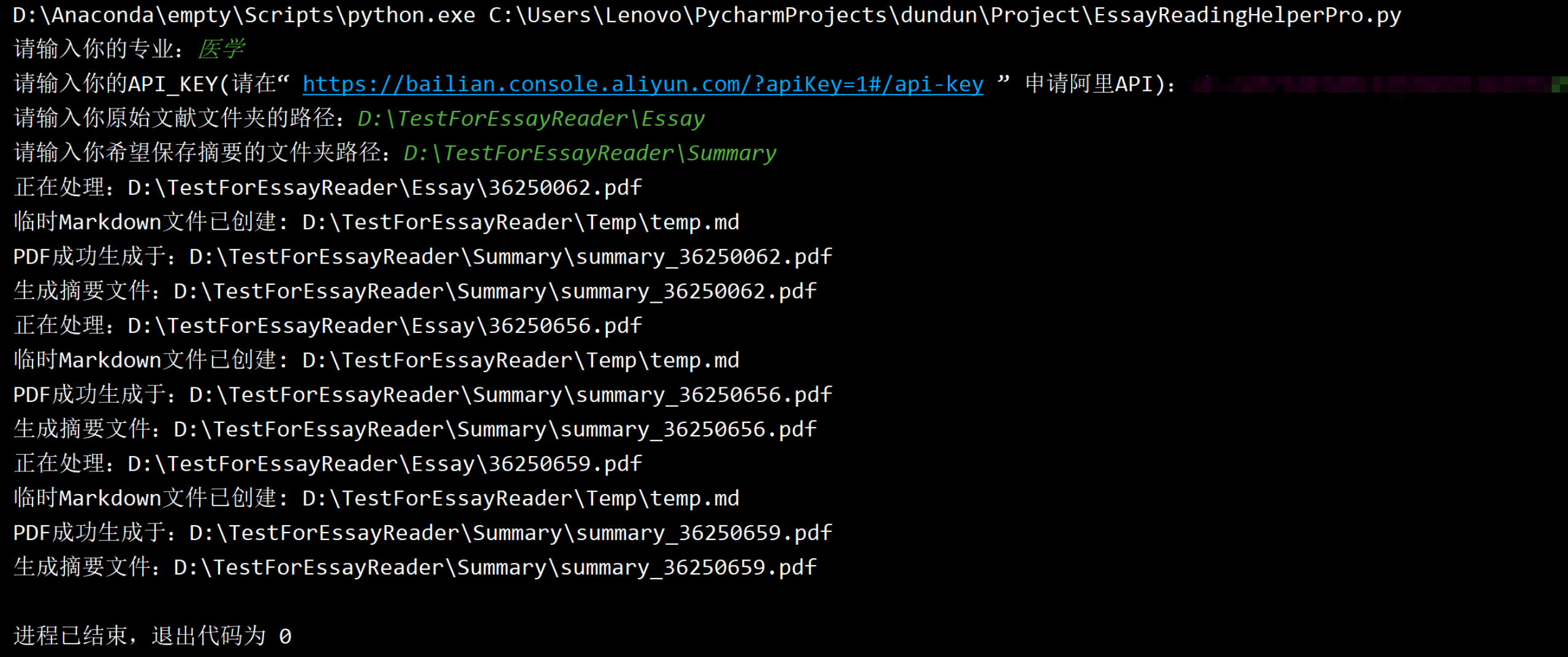
area = input("请输入你的专业:")
YOUR_API_KEY = input('请输入你的API_KEY(请在“ https://bailian.console.aliyun.com/?apiKey=1#/api-key ” 申请阿里API):')
essay_folder = input("请输入你原始文献文件夹的路径:")
summary_folder = input("请输入你希望保存摘要的文件夹路径:")
os.makedirs(summary_folder, exist_ok=True)
for filename in os.listdir(essay_folder):
if filename.lower().endswith(".pdf"):
pdf_path = os.path.join(essay_folder, filename)
print(f"正在处理:{pdf_path}")
text = extract_useful_text_from_pdf(pdf_path)
if not text.strip():
print("未提取到有效文本,跳过该文件。")
continue
markdown_summary = summarize_document(text)
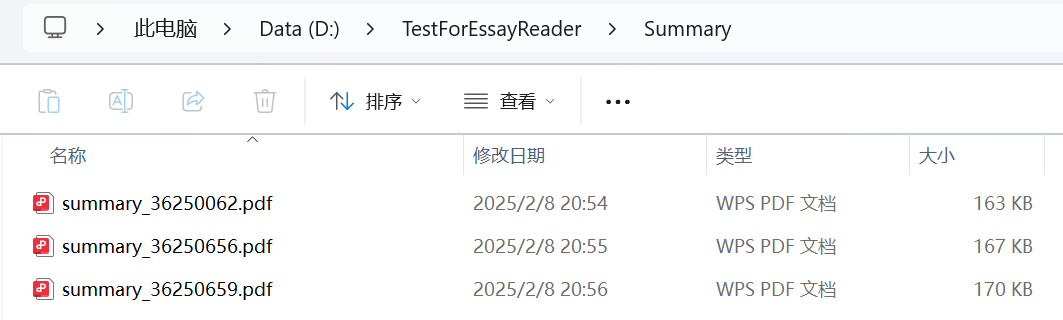
output_pdf = os.path.join(summary_folder, f"summary_{os.path.splitext(filename)[0]}.pdf")
convert_markdown_to_pdf(markdown_summary, output_pdf)
print(f"生成摘要文件:{output_pdf}")
if __name__ == "__main__":
main()
|